Tong's Digital Garden
welcome to Tong's Digital Garden
bigguaiwutong@qq.com
ElasticSearch 是什么
Elasticsearch是一个基于 Lucene 库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有Http Web接口和无模式 Json 文档。ElasticSearch 是用 Java 开发的,并在Apache许可证下作为开源软件发布。
建立搜索引擎
建立搜索引擎一般有三个过程:爬取数据,进行分词,建立倒排索引
爬取数据一般通过爬虫获取,所以不在 ElasticSeach 考虑的范围内
进行分词
分词:就是把内容拆分为很多个词语,ES是把text格式的字段按照分词器进行分词并保存为索引的
在 ElasticSearch 中是通过 Text Analysis(文本分析)将文本切分成词项的。文本分析的功能主要是通过 Analyzer(分析器)来实现的。
Analyzer由三部分组成:字符过滤器(Character filters)、分词器(Tokenizer)和词元过滤器(Token filter)。每一个Analyzer有且只能有一个tokenizer。
- Character filters:针对原始文本处理,例如去除html,阿拉伯数字转换等
- Tokenizer:按照规则将文本切分为单词
- Token Filter:将切分的单词进行加工,如单词小写、删除stopword、增加同义词等
建立倒排索引
倒排索引是什么
也常被称为反向索引、置入文件或反向文件,是一种索引方法,被用来存储在全文索引下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
示例
文本
T0 = 0. this is a text
T1 = 1. what is it
T2 = 2. I do not know what is that
我们可以得到的索引
a:{0}
this:{0}
text:{0}
it:{1}
i:{2}
do:{2}
not:{2}
know:{2}
that:{2}
what:{1,2}
is:{0,1,2}
当我们搜索 what is it 时,取 {1,2},{0,1,2},{1} 的交集,查询到 T1 文本
ElasticSearch
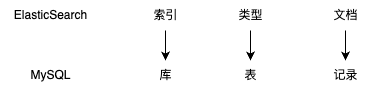
在 ElasticSearch 中有三个重要的专有名词:索引、类型、文档
索引:在 ElasticSearch 中的索引和 MySQL 中的索引有很大区别,是用来存放数据的地方,可以理解为一个数据库
类型:类型是用来定义数据结构的,可以认为是关系型数据库中的一张表
文档:文档对应的就是数据库中的一条数据
示例
建立索引 book
创建类型
"book":{
"properties": {
"word_count": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"title": {
"type": "text"
},
"publish_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd || epoch_millis"
}
}
}
文档
{
"word_count": 121212,
"author": "余华",
"title": "在细雨中彷徨",
"publish_date": "1994-09-27"
}
text 和 keyword 区别:首先 text 和 keyword 都是用来表示字符串的,但是 text 在存入 ES 时会进行分词,然后感觉分词内容进行反向索引,而 keyword 会直接根据内容建立反向索引
使用 ElasticSearch
怎么使用
ElasticSearch 公开了 所使用的 REST API,可以直接调用这些 API 来配置和访问 ElasticSearch 的功能。
对记录的增删改查
- 新增一条文档:IP:Port/Index/Type (PUT 请求)
- 删除一条文档:IP:Port/Index/Type/Id (PUT 请求)
- 修改一条文档:IP:Port/Index/Type/Id(DELETE 请求)
- 查看一条文档:IP:Port/Index/Type/Id(GET 请求)
- 查询文档:IP:Port/Index/Type/_search
- elasticSearch 的查询很特别,是 GET 请求,但是使用自己的查询语法,要求 GET 请求带有数据体
集群模式
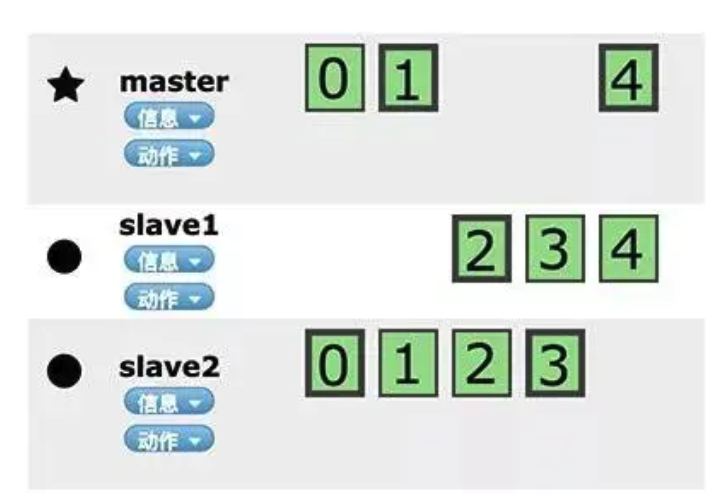
Elasticsearch 会对数据进行切分,同时每一个分片会保存多个副本,保证在分布式模式下的高可用。在 Elasticsearch 中,节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。
只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。